大数据存储笔记
第一章
产生背景
横向拓展,水平拓展;用更多的节点支持更大量的请求。
纵向拓展,垂直拓展;扩展一个节点的能力支撑更大量的请求。
大数据的特点:volume,velocity,variety,value
横向拓展需求、系统可靠可用、一致性需求在传统的关系模型下无法有效解决
大数据需要怎样的存储
大数据存储的集群系统,需要满足:
- 能够对集群内的计算机及存储资源进行统一管理、调度和监控
- 能够对集群内的数据进行分散存储和统一管理
- 集群内的计算机可以共同完成一个任务,分工协作、负载均衡
- 当集群中某一台计算机发生故障,集群可以保证功能的有效性、且数据不会丢失(分区容错性)
- 可以用简单的方式部署集群、扩展集群以及替换故障节点(伸缩性)
技术分类
• 按元信息管理方式划分:
对等节点的策略,由于没有中心节点的束缚有更高的可用性。
中心节点的策略,更好的可扩展性。
• 按数据模型划分:
针对不同业务模型出现的不同数据模型的数据库
• 分布式架构
Partition All -分库分表
Partition Engine -Share Nothing
Partition Storage -Share Storage 存算分离
NoSQL与newSQL
NoSQL是非关系型的数据库,主要用于解决SQL的可扩展性问题。不保证ACID特性,没有事务管理,无需多余操作就可以横向扩展;
NewSQL是关系型数据库,兼具Nosql数据库的海量存储管理能力和关系数据库的ACID特性和SQL便利性。
第二章
基于C/S的层次结构
AP与DP
AP是面向用户的应用处理器,用于完成数据处理的软件,能向CM传递用户的请求和数据。
DP是数据处理器,负责进行数据管理,类似一个集中式数据库管理系统,接受CM传递的命令和数据并给予反馈。
AP功能的变化
集中库 -不存储数据,相当于输入,主机运行了所有软件
多客户/单服务器 -应用、客户端服务(查询)、通信
多客户/多服务器 -应用、客户端服务(目录管理、缓存管理、查询处理、提交协议)、通信
瘦客户端/服务器 -客户端Server2Sever 上述功能转移给服务器,仅保留SQL接口与程序接口;AP是计算相关内容:目录管理、缓存管理、查询处理、事务处理、锁管理、访问控制。此外服务端还有存储相关功能:日志回放、故障恢复、索引设计、物理存储。
三种架构
个人理解,正确性不能保证。 参考文章
- 基于Server-to-server瘦客户端/服务器架构讨论的这三种分布式架构
- server-搜索引擎 -查询、优化、提取;并发控制;事务提交;
engine-事务部分(针对于恢复,因为需要日志,有状态)、索引、日志、故障恢复、物理存储的部分 - 三种架构的定义
- 各部分的可拓展性与兼容性特点
三种架构本质是newSQL想兼有SQL的强一致性、事务支持与NoSQL的易拓展性的不同实现方式,但又陷入可拓展性与兼容性的拔河比赛中。
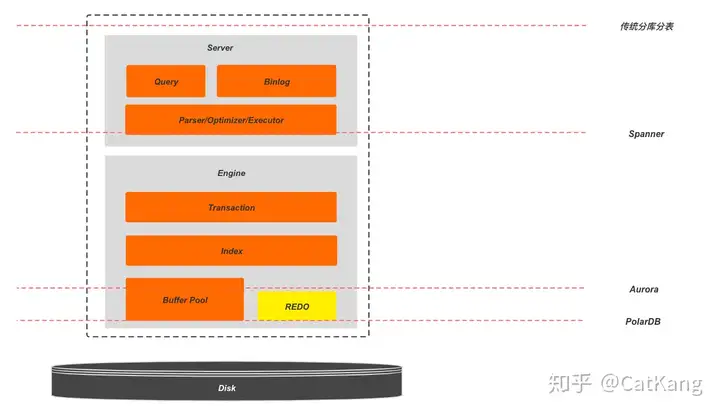
从上到下,依次是Partition ALL(分库分表),Partition Enginee(share nothing),Partition Storage(存算分离);从上到下可拓展性降低,换来生态兼容性的增加。
分库分表可拓展性极佳,性能高;但业务耦合大,通常需要根据业务场景设计,需要用户自己处理分片策略、分布式事务、分布式Query,通用性差。每个节点都是完整的DBMS。
Share Nothing只在引擎层做分片,节点间相对独立。相对于传统的分库分表,将分布式事务与分布式查询等问题放到了数据库内部处理,向用户屏蔽了分布式事务等细节,提供统一的数据库服务,简化了用户使用。
尴尬的是,大多数分库分表的实现也会通过中间件(数据处理、数据管理、负载均衡、驱动数据库) 的引入来屏蔽分布式事务等实现细节,同样采用类Multi Paxos这样的一致性协议来保证副本一致,同样对用户提供统一的数据库访问,那么相较而言,Partition Engine的策略优势好像又没有很大。
继续将分片的分界线下移,到事务及索引系统的下层。这个时候由于Part 1部分保留了完整的事务系统,已经不是无状态的,通常会保留单独的节点来处理服务。这样Part 1主要保留了计算相关逻辑,而Part 2负责了存储相关的像REDO,刷脏以及故障恢复。因此这种结构也就是我们常说的计算存储分离架构,也被称为Share Storage架构。
由于保持了完整的计算层,所以相对于传统数据库需要用户感知的变化非常少,能够做到更大程度的生态兼容。同时也因为只有存储层做了分片和打散,可扩展性不如上面提到的两种方案。
DDBS的组件结构
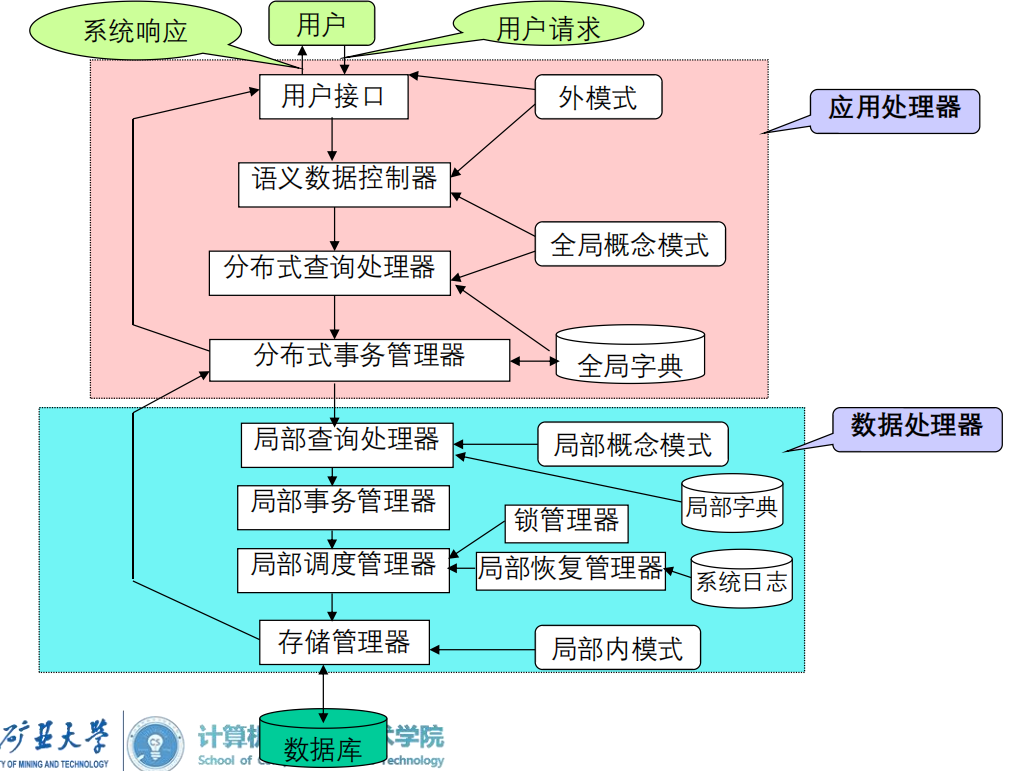
– 应用处理器(AP)功能:
用户接口:检查用户身份,接受用户命令(如SQL)
语义数据控制器:一些约束(视图管理、安全控制、语义完整性控制)
全局查询处理器:将用户命令翻译成数据库命令;生成全局查询计划;收集局部查询结果并返回给用户
全局执行监控器(全局事务管理器):调度和监视AP和DP;保证复制数据的一致性;保证全局事务的原子性
– 数据处理器(DP)功能:
局部查询处理器:全局命令 —> 局部命令;选择最好的访问路径去执行
局部事务管理器:以局部子事务为单位进行调度执行
局部调度管理器:负责局部场地上的并发控制
局部恢复管理器:维护本地数据库一致性的故障恢复
存储管理器:访问数据库;控制数据库缓存管理器;返回局部执行结果
DDBS的模式结构
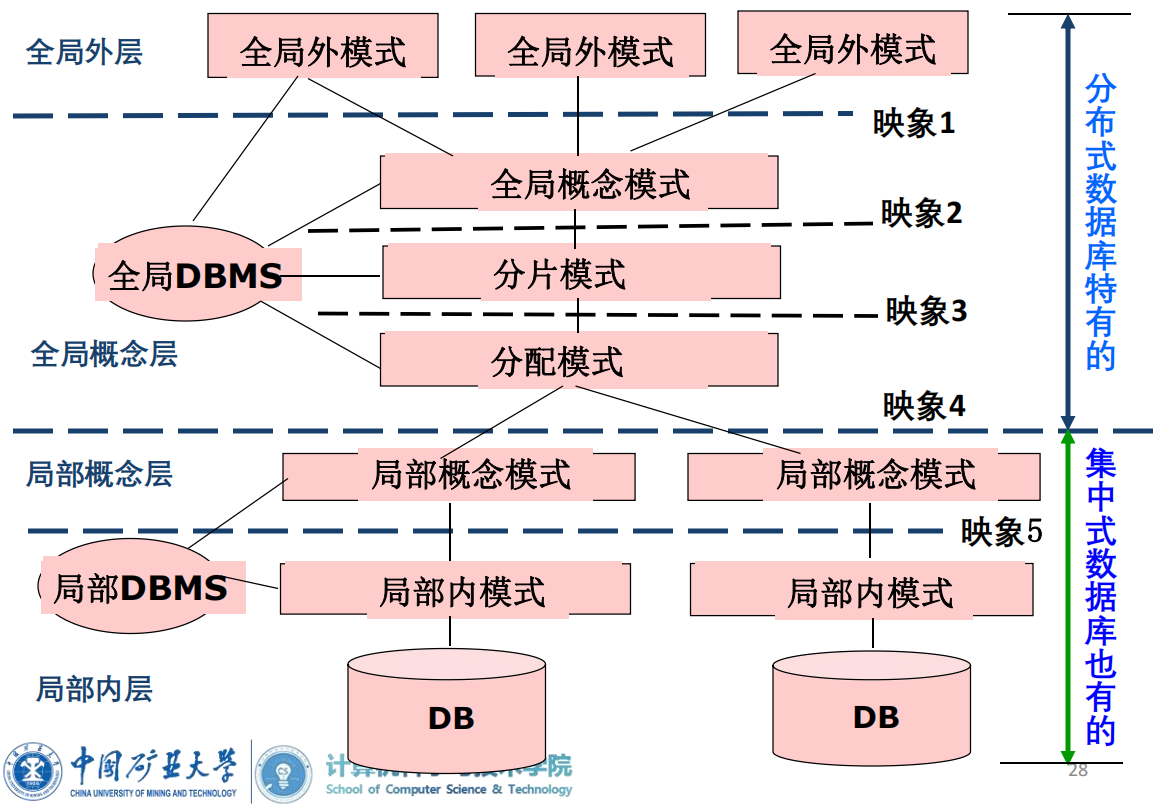
- 全局外模式(GES): 全局外模式即全局用户视图,是分布式数据库的全局用户对分布式数据库的最高层抽象。
- 全局概念模式(GCS): 全局概念模式即全局概念视图,是分布式数据库的整体抽象,包含了全部数据特性和逻辑结构。全局概念模式再经过分片模式和分配模式映射到局部概念模式。
- 分片模式是描述全局数据的逻辑划分视图。即全局数据逻辑结构根据某种条件的划分,将全局数据逻辑结构划分为局部数据逻辑结构。每一个逻辑划分成一个分片。在关系数据库中,一个关系中的一个子关系称该关系的一个片段。
- 分配模式是描述局部数据逻辑的局部物理结构,即划分后的分片的物理分配视图。
- 局部概念模式(LCS) :局部概念模式为局部概念视图,是全局概念模式的子集。局部概念模式用于描述局部场地上的局部数据逻辑结构。当全局数据模型与局部数据模型不同时,还涉及数据模型转换等内容。
- 局部内模式(LIS) :定义局部物理视图,是对物理数据库的描述,类似集中数据库的内层。
DDBS的数据透明性
- 分片透明性:分片是将一个关系分成几个子关系,每个子关系称为一个分片。用户不必考虑数据属于哪个分片的性质称为分片透明性。位于全局概念模式和分片模式之间。
- 分配透明性:分布数据库支持有控制的数据冗余,即数据可重复存储在不同的场地上。用户不必考虑各个片段的存储场地称为分配透明性。位于分片模式和分配模式之间。
- 局部映射透明性:用户不必考虑数据的局部存储形式称为局部映射透明性。位于分配模式与局部概念模式之间。
select . from S --分片透明性 select . from S1 & S2 --分配透明性 select . from S1 at site1 --局部映射透明性 Execute:$SUPIMS($SNO,$FOUND,$SNAME) at L1 --不透明
MDBS V.S. DDBS 4点
分布式数据库系统:是自上而下(top-down) 地设计数据库,可灵活地进行分片和分配设计。但分布式数据库系统具有数据库组件数量的限制,通常不多于数十个数据库组件。
多数据库集成系统:数据和数据库已存在,是遵循自下而上(bottom-up) 地集成各局部场地上的数据。数据集成系统通过约束数据管理能力(只支持读) ,可将数据库组件数量扩展到数百个。
二者都需要为用户提供统一的存取数据环境,数据都分散存储,区别在于:
- 数据模式是否预先定义
- DBMS是否同构
- 查询优化策略是否自动生成
- 是否一定存在局部用户(MDBS是)
第三章
3.1 分布式数据库设计(分片,分配,复制)
3.1.1 设计的策略与步骤
自顶向下,需求分析->概念设计->分布设计->物理设计->性能调优
3.1.2 分片的定义及作用
分片(Fragmentation):对全局数据的逻辑划分。
分配(Allocation):对片段的存储场地的指定,称为分配。当片段存储在一个以上场地时,称为数据复制(Replication)。如果每个片段只存储在一个场地,称为数据分割(Partition)存储。
分片的作用:
- 减少网络传输数据量
- 增大事务处理的局部性
- 提高数据的查询效率和系统可靠性
- 使负载均衡
分片过程是将全局数据进行逻辑划分和实际物理分配的过程。全局数据由分片模式定义成各个片段数据,各个片段数据由分配模式定义存储在各个场地。
分片的原则:完备性(数据不丢)、可重构性(关系不丢)、不相交性(形式化描述)
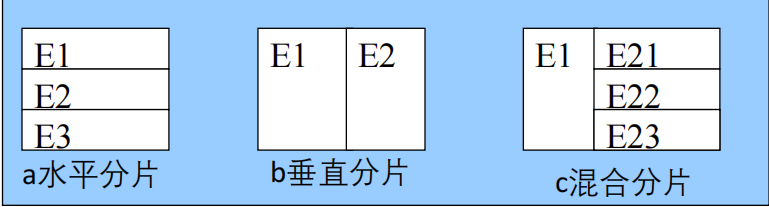
分片的种类:水平分片(按元组)、垂直分片(按属性)、混合分片
3.1.3 水平分片
水平分片:选择
导出式:半联接
设计依据分片的需求信息,来源于应用因素和数据库因素
设计准则:定义具有完备性和最小性的一组简单谓词集
3.1.4 垂直分片
分片表示:投影运算
完备性证明:并运算(属性)
可重构性证明:连接运算
不相交性证明:交运算,结果不是空,是主关键字
3.1.5 分片的表示方法
图形表示法(表格)和树形表示法
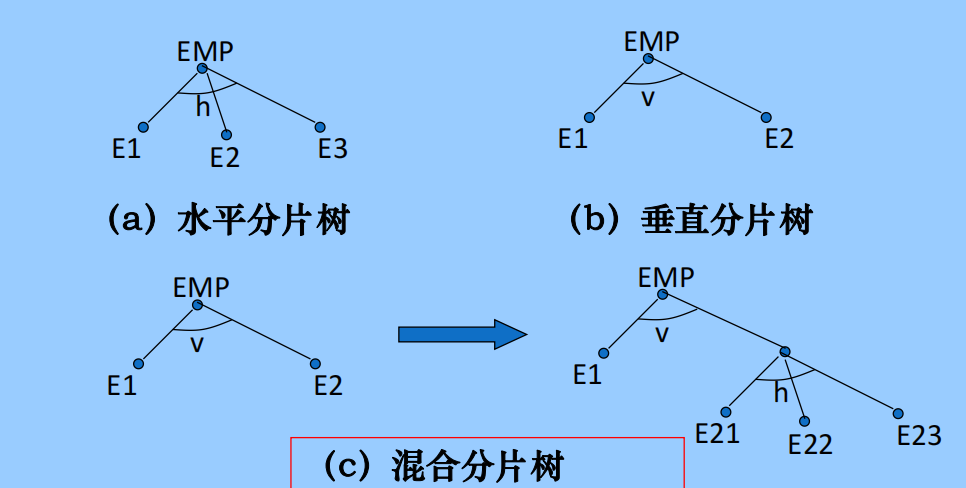
3.1.6 分配设计
片段到物理场地存储映射的过程称为分配设计的过程。
- 非复制分配
如果每个片段只存储在一个场地上,称为分割式分布,对 应的分布库,称为全分割式分布库。 - 复制分配
如果每个片段在每个场地上存有副本,称为全复制分配,对应的分布库称为全复制分布库。
如果每个片段只在部分场地上存有副本,称为部分复制分配,对应的分布库称为部分复制分布库。
3.1.7 数据复制技术
同步复制与异步复制;主从复制与对等复制;
3.2 分布式查询优化
(体现关键步骤,分片展开等,∪是二元运算,圈空)
3.2.1 查询优化的意义
3.2.2 查询处理器
3.2.3 查询分解
基于全局概念模式将演算查询分解为代数查询。得到全局逻辑查询计划树。以下五步:
- 查询规范化(交换律结合律分配律)
- 语法及语义分析(语法错误、无意义的查询、无权限,通过查询图)
- 查询约简
- 查询重写
3.2.4 数据局部化
将全局表利用并运算和连接运算分解为局部表
先画出全局树,优化全局树,转换为片段查询树,
及时将选择运算、联接运算置空,并将∞下移到∪之前执行(利用分配律)
3.2.5 片段查询的优化
3.3 分布式存取优化
3.3.1 基本概念
3.3.2 优化的理论基础
关系的基: 指关系R包含的元组个数,记为Card(R)
• 属性的长度:指属性A定义的取值字节数,记为Length(A)
• 元组的长度:关系R中每个元组的字节数,记为Length(R),
Length(R)=∑Length(Ai)
• 关系的大小:关系R所包含的字节数,记为Size(R)
Size(R)=Card(R) Length(R)
• 属性的特征值:指关系R中属性A取值不同的属性值个数,
记为Val(A)
• 属性A的最大值和最小值:记为Max(A)和Min(A)
选择运算:
基数:Card(S)=ρ Card(R)*
ρ的计算:仅考虑选择属性A条件的等值情况**,其中A是R的属性,X是常数。 则
Val(S,B)的计算:
当属性B属于选择条件时,Val(S,B)=1
当属性B为关键字(主键)时,Val(S,B)=ρ Val(R,B)
当属性B不属于选择谓词时,
联接运算:
半连接运算:
3.3.3 半连接优化方法

就是看绕这么一圈,半连接付出的代价有没有全连接多。
作业一 分片设计
存在一个商品购物系统,系统中包含两个全局关系:用户表USER(UID,UNAME,ADDRESS,HOBBY,CITY) 和订单表ORDER(UID,PID,PRICE) ,UID为用户编号,UNAME为用户姓名,CITY为所在城市。PID为商品编号,PRICE为订单总价,UID在USER表中是主键,在ORDER表中是外键。先要进行分布式数据库的建立,分片的规则是:
(1)关系USER按属性敏感程度垂直分片
U1包含非敏感属性:UID,UNAME,CITY
U2包含敏感属性:ADDRESS,HOBBY
(2)USER中的所有非敏感属性再根据CITY进行水平分片
U11:CITY IN { 北京,上海,广州,深圳}
U12:CITY NOT IN { 北京,上海,广州,深圳}
(3)关系ORDER按照和USER 的连接关系进行分片,得到O1和O2 。
作业二 查询优化
查询Q: “查询“徐州市”用户购买商品编号为“P1”的所有订单,获取订单中的用户编号、用户姓名、商品编号和订单总价” 。
(1)写出查询Q的关系代数表达式,并变换到片段查询
(2)对片段查询树进行优化
作业三 存取优化
如下图
第四章 HBase
HDFS的问题
- 不支持对数据的随机改写
- HDFS没有数据包的概念
- HDFS无法针对行数统计、过滤扫描等常见的数据查询功能实现快捷操作,一般需要通过Mapreduce实现。
- (优势是大文件存储、多副本、自动分块)
HBase的特点
- 底层采用HDFS存储,但文件结构和元数据由自身维护。
- 采用面向列+键值对的存储模式
- 可实现便捷的横向拓展
- 可以实现自动的数据分片
- 较为严格的读写一致性和自动故障转移
- 对全文的检索与过滤
优点在于擅长处理大量数据的写入、高性能、高可靠、可拓展;缺点是不支持表的关联查询分析等。
Region
Region server是存放Region的容器;Region是表的数据的一部分,一个Region相当于关系数据库中表的一个分片。一个表可能存放于不同的Region中。
特点:
- Region不能跨服务器,一个Region Server会有一个或多个Region;
- 数据量增大时,Region会发生分裂;
- 处于负载均衡的需要,Region会发生迁移;
- Region所有的数据存取操作都是调用HDFS的客户端接口实现的。
同一个表不同行的数据可以存放在不同的服务器,同一个表相同行的数据也可以存放在不同的服务器。这句话如何理解?(
我不理解,我觉得后半句有问题。)
一个服务器是Region的存储机构,但存储一个Region不代表存储一个表;每个Region都包含若干个Store,一个Store就是一个列族,是把列族作为对象存储的,不一定是一个表的,可能是不同表的分片。
预写日志WAL:先写到WAL中(一个Regionserver就一个WAL),在加载到memStore中;
每个region内部都有多个store实例,每个store对应一个列族;每个store中有一个memStore实例,当memStore满了,HDFS就会生成一个新的HFile(用LSM树来存储,会在最终刷写之前进行快速排序,使随机写入的数据实现顺序存储,提高读取效率);memStore可以看作在内存中的缓存,无论读写,都会先看memStore。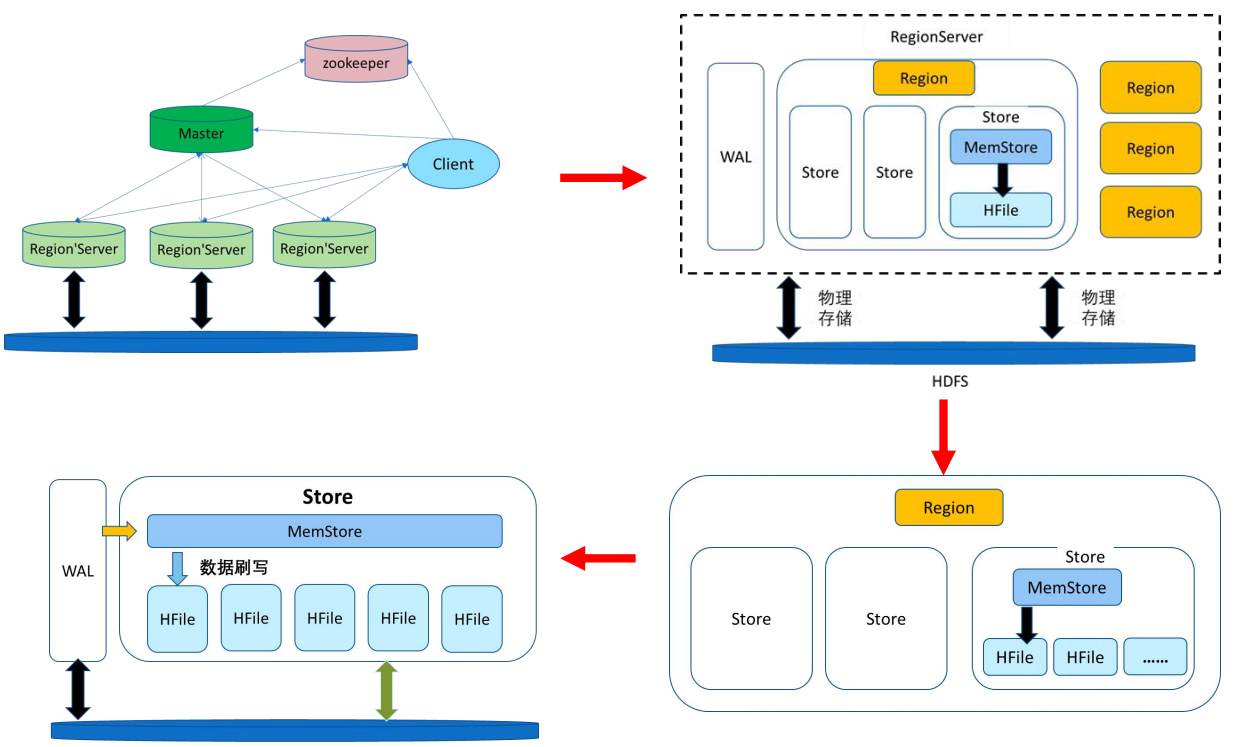
增删改操作
- HBase新增单元格,在HDFS上增加一条数据
- HBase修改单元格,在HDFS上增加一条数据,但版本号比之前的大
- HBase删除单元格,在HDFS上增加一条数据,但是这条数据没有value,类型为Delete,即墓碑标记(Tombstone),在执行HFile的合并时,会真正删除这些记录。
读写流程
参考文章:HBase读写流程
Zookeeper(ROOT)->RegionServer(META)->Region->memStoore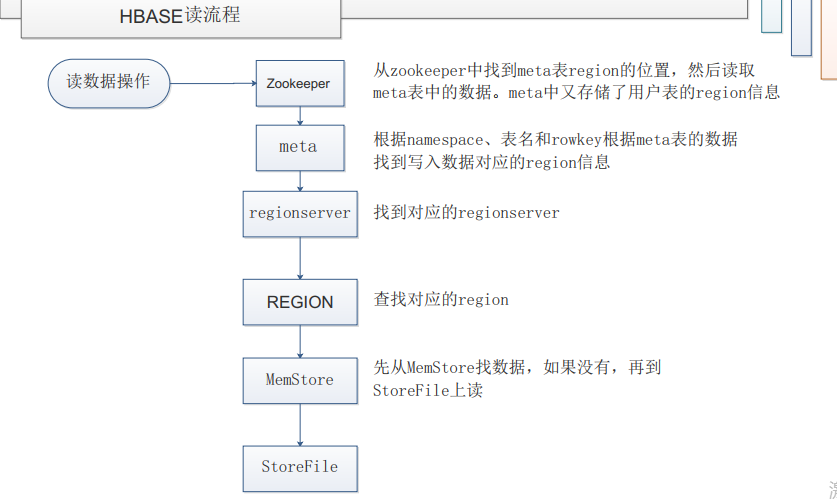
客户端访问,zookeeper的/hbase/meta-region-server节点查询到哪台RegionServer上有hbase:meta表
客户端连接含有hbase: meta表的regionserver。Hbase: meta表存储了所有的Regin的行键范围信息,通过这个表可以查询到请求行键所在的Region,以及这个Region所在的RegionServer
客户端在对应的RegionServer上,先从MemStore,再到HFile中找需要的信息。
第一次访问后,客户端会把meta信息缓存起来(BlockCache) ,下次操作直接从BlockCache中查找meta信息。
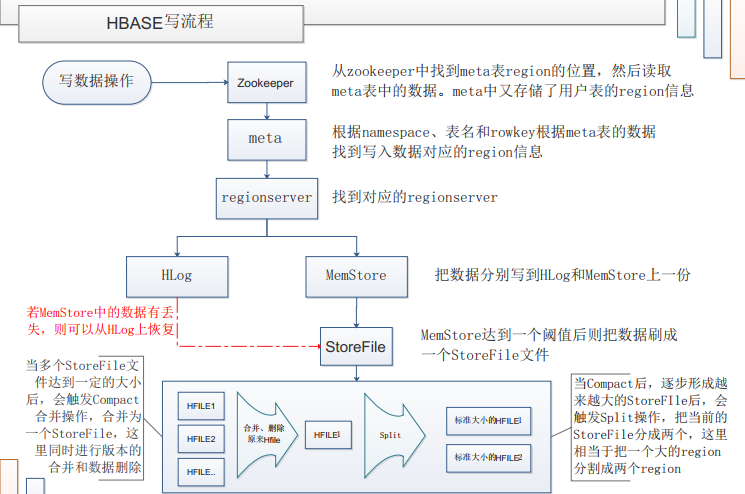
客户端访问,zookeeper的/hbase/meta-region-server节点查询到哪台RegionServer上有hbase:meta表
客户端连接含有hbase: meta表的regionserver。Hbase: meta表存储了所有的Regin的行键范围信息,通过这个表可以查询到请求行键所在的Region,以及这个Region所在的RegionServer
客户端在对应的RegionServer上,把数据分别写到Hlog和memstore各一份
当memstore达到阈值后把数据刷成一个HFIle文件,当compact后,逐渐形成越来越大的HFIle后触发spilt,把当前的HFIle分成两个,这里相当于把一个大的region分割成两个region
若MemStore中的数据有丢失,则可以从HLog上恢复,当多个HFIle文件达到一定的大小后,会触发Compact合并操作,合并为一个HFIle,这里同时进行版本的合并和数据删除
Rowkey设计
- 三原则:长度原则(越短越好),散列原则(数据均衡分布),唯一原则
- 加盐salting,在rowkey前分配随机数;随机前缀可以让他们分不到不同的Region中。
- 预分区,解决Region自动拆分带来的热点问题和拆分合并问题(也可预留拓展);比如生成0-499的随机数,规定0-50,50-100…等Region的范围。
- 散列,解决如同一用户同一天数据集中存放的需求;将某一参数(如uid,date)传入哈希,结果模500,余数加到首部,可再结合预分区,就能在满足需求的同时让数据均匀分布到Regionserver中。
- 反转,牺牲rowkey的有序性换随机性;解决开头固定结尾变化的热点问题,如手机号;用于时间(Long.MAX_VALUE - timestamp)可满足最近记录优先的需求。
第五章 大数据索引结构
三种基本的数据存储引擎分别是哈希(高效随机查找)、B树(高效范围查找)、LSM树(Log-Structured Merge Tree)。HBase的一个列族就是一颗LSM树,内存部分是跳表,外村选择了布隆过滤器来快速判别。
跳表
跳跃表(Skip List)是一种能高效实现插入、删除、查找的内存数据结构,这些操作的复杂度都是
应对场景:快速写入,需要更新代价低,支持区间查询;与B+树的不同就在于更新代价低,因而适用于大数据场景。
跳跃表的构建:
•1、给定一个有序的链表。
•2、选择链表中最大和最小的元素,然后从其他元素中按照一定算法(随机) 随即选出一些元素,将这些元素组成有序链表。这个新的链表称为一层,原链表称为其下一层。
•3、为刚选出的每个元素添加一个指针域,这个指针指向下一层中值同自己相等的元素。Top指针指向该层首元素
•4、重复2、3步,直到不再能选择出除最大最小元素以外的元素。
跳跃表的插入流程:
插入跳表时,新入节点要以一定概率在上层生成索引。
找到待插入元素的前驱节点->插入->随机生成高度值->按高度值修改索引
LSM树
为什么说LSM树是一种写入友好的数据结构?
LSM树对写入更友好,写入操作都是顺序写,利用了HDFS的优点。
顺序写入:LSM树的写入操作是以顺序写的方式进行的。这是因为新数据被追加到磁盘上的顺序日志(SSTables)中,而不是直接写入到原始数据文件中。相比于传统的随机写入操作,顺序写入的开销更小,能够极大地提高写入性能。
延迟合并:LSM树的合并操作通常是延迟执行的,也就是说,多个SSTables之间的合并并不是在每次写入操作之后立即执行的。这样可以避免在写入过程中频繁地进行合并操作,从而减少了写入的延迟和开销。
内存缓存:LSM树通常会在内存中维护一个数据缓存区,用于存储最近写入的数据。即使在刷写flush到硬盘,内存中也会开辟新的memstore来为新的写入服务。这样可以避免每次写入都要访问磁盘,提高了写入性能。同时,内存缓存中的数据也可以通过定期刷新到磁盘上的SSTables中,以保证数据的持久性。
应对场景:高吞吐量(顺序)写入,随机查找,可拓展性(LSM树允许数据分区)。
compaction:将key值相同的数据全局综合圈起来,选择合适的版本交给用户。
主要有两种类型:
major compact:不宜频繁使用
优点:合并之后只有一个文件,读取性能最高
缺点:合并所有的文件需要很长的时间,消耗大量带宽。
minor compact:
优点:局部的compact操作,少了IO,减少文件个数,提升读取性能。
缺点:全局操作,无法在合并过程中完成。
布隆过滤器
解决问题的类型:有效排除一些肯定不在数据库中的数据;
实现原理:通过一个数组和多个哈希函数实现,对与每一个数据,做k次哈希,每次哈希结果对应数组位置置为1;如果查询一个数据,发现所有哈希结果指示的位置都为1,则该数据可能在数据库中,否则一定不在数据库中。
为什么说HBase是一种“顺序写入,随机查找”的分布式数据库?
随机查找:尽管HBase采用了LSM树的索引结构,但HBase的查询操作并不是基于LSM树进行的,而是基于HBase表中的行键(row key)进行的。Region组织的元信息。
第六章 一致性
分布式事务
事务是数据库中的一段操作序列,要么全做,要么不做;由三部分组成:开始标识,操作,结束标识(commit or abort);按照组成结构可以分为平面事务(事务自治、独立)与嵌套事务(一个事务的执行包括另一个事务,内子外父);
嵌套事务的特点
- 提交依赖性:子事务的提交必须等待父事务的提交;
- 废弃依赖性:父事务废弃,子事务必须废弃;
分布式事务的一致性
这个问题是由于分布式数据库中存在数据复制造成的(也带来了可靠可用性);
三种级别:
- 强一致性:更新过即刻访问
- 最终一致性:一段时间后可访问
- 弱一致性:不可访问(网购评论、广告)
CAP
一个分布式系统不可能同时满足一致性、可用性与分区容错性,最多俩;
- 一致性是数据在多个副本之间保持一致的特性;
- 可用性是提供的服务一直处于可用的状态——在有限时间内返回结果;
- 分区容错性,在遇到网络分区时,仍然保证可用性和一致性的服务;
例如,同时写北京和广州的DB都成功才返回成功且网络故障时提供降级服务(不可访问),满足CP。
BASE
Bascially Available, Soft State, Eventually consistent; 是对CAP中可用性和一致性权衡的结果;
出现故障时允许损失部分可用性;软状态指允许数据存在不一致的中间状态,认为不影响可用性;所有数据副本在经过一段时间后,最终都能达到一致的状态;
总的来说,BASE理论面向的是大型高可用可扩展的分布式系统,和传统的事物ACID特性是相反的,它完全不同于ACID的强一致性模型,而是通过牺牲强一致性来获得可用性,并允许数据在一段时间内是不一致的,但最终达到一致状态。
HBase的ACID特性(了解)
原子性:只保证WAL的原子性;
一致性:强一致性;
2PC(重点)
分布式数据库中的全局事务由被分解为在各个场地上执行的子
事务所组成。只有当各个场地上的子事务都正确执行后,全局
事务才可以提交。只要有一个子事务不能提交,则全局事务应
该废弃,接下来所有的子事务也应全部废弃。因此,所有子事
务均可以正确提交是分布式事务提交的前提。
执行流程
决定阶段:有协调者发送预提交(prepare) 命令,然后等待参与者的应答。如果所有的参与者都返回“准备提交(ready) ”。那么协调者做出提交决定;如果至少有一个参与者返回“准备废弃”,那么协调者做出废弃决定。
执行阶段:协调者把在决定阶段做出的决定发送给参与者。如果协调者向各个参与者发“提交”(Commit) 命令,各个参与者执行提交;如果协调者向各个参与者发出“废弃”(Abort) 命令,各个参与者执行废弃,取消对数据库的修改。无论是“提交”还是“废弃”,各参与者执行完毕后都要向协调者返回“确认”(Ack) 应答,通知协调者执行结束。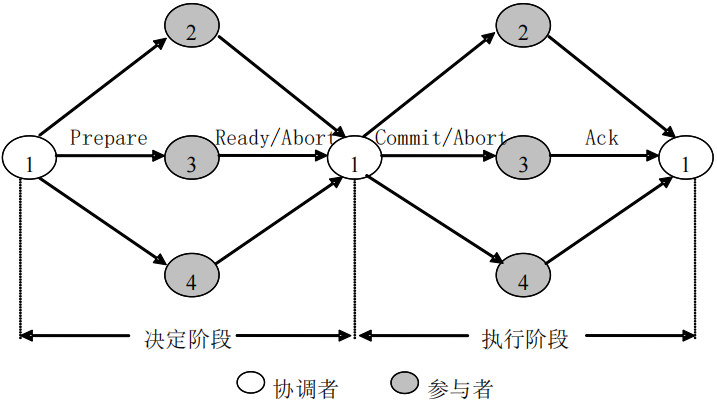
存在的问题
同步阻塞,单点问题,数据不一致,过于保守
协调者故障,参与者占着资源却不能执行事务,进入阻塞状态;可用三段提交协议避免,若已经阻塞,则使用终结协议恢复。
步骤1:选择参与者PT作为新的协调者。
步骤2: PT向所有参与者发送“访问状态”命令,各参与者返回自身的状态。
步骤3: PT 根据各参与者当前的状态做出决定:
- 若部分参与者处于“初始”状态,部分参与者处于“准备就绪” 状态,则PT 发送abort命令;
- 若所有参与者均处于“准备就绪”状态,则PT 发送Commit命令;
- 若至少一个参与者处于 “提交”状态,则PT发送Commit命令;
- 若至少一个参与者处于“废弃”状态,则PT发送abort命令;
Paxos
Prepare->Accept->Learn
Proposer,Accepter,Learner
第七章 并发控制
目的
并发控制的主要目的是保证事务的隔离性,最终保证数据的一致性;解决并发带来的丢失修改、不可重复读、读脏数据的问题;并发控制就是利用正确的方式调度并发操作序列,避免数据不一致;保证一个事务的执行不受其他事务的干扰,保证事务并发执行的可串行性。
可串行化
如果一个事务最后一个操作在另一个事务之前,或反之,则是串行调度。
等价判别:冲突操作顺序一致
可串行化:等价于串行调度
分布式事务的可串行化:
n个事务在m个场地上的并发序列记为E;
当每个场地的局部调度是可串行化的 并且 在总序中如果有
设数据项a,b存放在S1场地,x,y存放在S2场地。有分布式事务T1和T2,判断下面的每个执行是否是局部可串行的,是否是全局可串行的,分别说明理由。
1、执行1:在S 1场地R 1(a) R 2(a) W 2(b) W 1(a) ,
在S 2场地R 1(x) W 1(x) R 2(y) W 2(x) ,
2、执行2:在S 1场地R 1(a) R 2(a) W 1(a) W 2(b)
在S 2场地W 2(x) R 1(x) R 2(y) W 1(x) 。分布式并发控制
分布式数据库并发控制是指在分布式数据库系统中,为了保证数据的一致性和完整性,同时满足用户并发访问的需求,采用一定的技术手段对并发访问进行控制的过程。它主要解决的问题包括以下几个方面:
数据一致性问题:在分布式环境下,由于数据可能分散在多个节点上,因此必须采取措施保证多个节点之间数据的一致性,避免数据冲突和不一致的问题。
并发控制问题:多个用户可能同时对同一份数据进行读写操作,因此需要采取并发控制策略,保证数据的正确性和完整性,同时最大化地发挥系统的并发处理能力。
三种典型的分布式锁
数据库(MySQL)方式:用一张表做锁,加锁是往里面用资源ID做主键插入记录,解锁则删除;
Redis分布式锁:setnx,setnx是set if not exists的缩写;若key不存在,则将key的值设置为value;当key存在时,不做任何操作。解锁del key;
Zookeeper分布式锁:创建一个目录用于锁管理,加锁在该目录下创建临时顺序节点,如果顺序号最小则获得锁,否则监听目录等待;解锁则删除节点;
对比:
- 从理解的难易程度角度(从低到高)数据库 > 缓存 >Zookeeper
- 从性能角度(从高到低)缓存 > Zookeeper >= 数据库
- 从可靠性角度(从高到低)Zookeeper > 缓存 > 数据库